-
Noise Suppression미분류 2021. 2. 16. 15:47

이미지 출처: pixabay.com 상대방과 통화를 하던 중에 자신 또는 상대방이 시끄러운 곳에 있어서 서로의 목소리가 잘 들리지 않았던 경험, 한번 쯤 있으실텐데요. 옆 집 공사 소리, 길거리 소음, 카페 음악 소리 등 다양한 잡음(noise)이 목소리에 섞여버려서, 서로의 말이 잘 전달되지 않는 문제입니다. COVID-19로 인해 재택근무를 하며 화상 회의/수업을 자주 하다보니, 이러한 문제가 더 피부에 와닿습니다.
본 포스팅에서는 noise suppression(잡음 제거)라는 task에 대한 기본적인 소개를 한 뒤, 이와 관련된 성능 평가 지표들을 알아보겠습니다.
1) Noise Suppression?
잡음이 섞인 목소리로부터 잡음을 억제하고 깔끔한 목소리를 추출해내는 기술을 noise suppression(잡음 제거)라고 합니다. 오디오/신호 처리 분야에서 noise suppression과 헷갈리기 쉬운 용어들로는 denoising, noise cancelling, source separation, speech enhancement 등이 있습니다. 상황에 따라 용어가 혼용되기도 해서, 논문을 읽다보면 각각의 경계에 대해 의문이 들 때도 있습니다. 한글로 번역을 하는 것은 어색한 터라, 되도록 영어 표현을 그대로 사용하겠습니다. 우선 간단하게 각각을 소개하며 그 경계를 짚어보겠습니다.

이미지 출처: https://www.apple.com/airpods-pro 1-1) Noise Suppression != Active Noise Cancellation(ANC)
에어팟 열풍이 불면서 "노이즈 캔슬링"이라는 용어를 많이 들어보셨을 것입니다. 에어팟 프로의 노이즈 캔슬링 기능을 키면 주변 소리가 차단되는데, 이 때 에어팟 프로가 수행하는 역할은 엄밀히 말해서 noise suppression이라기 보단 active noise cancellation(ANC)입니다. 주변으로부터 들어오는 파장과 반대되는 파장을 쏴줌으로써, 사람의 귀에 들어오는 단계에서부터 잡음을 능동적으로 차단해주는 것이 ANC입니다.
Noise suppression는 다음과 같은 예시 상황을 통해 설명할 수 있습니다. 카페에 있는 A씨와 헬스장에 있는 B씨가 noise suppression기능이 지원되는 서비스로 통화를 한다고 가정합시다. 통화를 하는 동안 카페에 있는 A씨의 귀에는 주변 테이블의 소음이 충분히 잘 들립니다. 하지만 A씨의 말이 B씨에게 전달될 때에는, noise suppression 기능을 통해 그 소음이 제거됩니다. 그리하여 B씨 귀에는 깨끗한 A씨의 목소리만 들립니다. 이와 마찬가지로 A씨 또한, 헬스장의 시끄러운 음악소리가 제거된 B씨의 깨끗한 목소리만 들을 수 있습니다.
Denoise는 이들을 범용적으로 통칭할 수 있는 용어입니다. Active noise cancelling이 하드웨어 레벨의 denoising 솔루션이라면, noise suppression은 소프트웨어 레벨의 denoising 솔루션으로 생각하면 되겠습니다.
1-2) Source Separation vs. Speech Enhancement

이미지 출처: source-separation.github.io 음원을 영어로 하면 "sound source"인데, 이를 보통 줄여서 source라고 지칭합니다. Source separation(음원 분리)이란, 여러 개의 source가 섞인 mixture로부터 각각의 source를 분리해내는 작업을 의미합니다. 보통 mixture를 구성하는 source들에 대한 정보가 전혀 주어지지 않기 때문에, 이러한 작업을 일반적으로 BASS(Blind Audio Source Separation)라고 지칭합니다. Source가 사람의 목소리가 될 수도 있고, 서로 다른 악기의 소리가 될 수도 있습니다. 사람의 목소리가 source일 경우, "Speech separation"이라고 표현하기도 합니다. Noise suppression은 source와 noise가 섞인 mixture로부터 source를 분리해내는 작업이기 때문에, 큰 틀에서는 speech separation에 포함된다고도 볼 수 있습니다.
Speech enhancement의 경우 타겟 음성(target speech)이 존재하여 그를 추출해내는 것이 목표입니다. 만약 타겟 음성 한 명과 기타 잡음이 섞인 mixture로부터 타겟 음성만을 추출해낸다면, 이를 noise suppression이라고 볼 수 있습니다. 만약 타겟 음성 한 명과 다른 사람들의 목소리가 섞인 speech source mixture로부터 타겟 음성을 추출해낸다면? 다른 사람들의 목소리를 noise로 해석한다면 이 또한 noise suppression으로 볼 수 있겠습니다만, 보통 이러한 task는 target speech enhancement라고 지칭하는 추세입니다.
1-4) DL in noise suppression
본 포스팅에서는 구체적인 딥러닝 모델들을 소개하는 대신, 일반적인 접근 방식(approach)만을 간단히 소개하도록 하겠습니다. Noise suppression에 딥러닝을 활용하는 최초의 연구는 A Regression Approach to Speech Enhancement based on Deep Neural Networks로, 이후에 등장하는 연구들도 큰 틀에서는 비슷한 접근 방식을 취하고 있습니다.

이미지 출처: Nvidia blog Noise suppression 모델의 목적이 noisy source로부터 target source를 분리해내는 것이기 때문에, 모델 학습을 위해서는 noisy source와 target source가 모두 필요합니다. Noisy source는 구하기 쉽지만, 그에 대응되는 깨끗한 target source를 구하기는 쉽지 않죠. 그렇기 때문에 보통 실험 데이터셋을 생성하기 위해 깨끗한 target source 데이터셋과 noise 데이터셋을 마련하고, 이를 인위적으로 합성하여 noisy speech를 생성합니다. 이렇게 인위적으로 생성된 noisy speech를 noise suppression 모델의 인풋으로 넣으면, 아웃풋으로 target source가 분리되게끔 학습하는 것이 뉴럴 네트워크의 목표입니다.
2) Evaluation Metrics
Source separation 모델의 성능은 주로 objective evaluation(객관 평가) 및 subjective evaluation(주관 평가)를 통해 측정됩니다. Subjective evaluation은 실험 참가자를 모집하여 분리된 음원의 퀄리티에 점수를 매기는 방식을 의미하는데, 참가 인원을 모집하고 실험을 진행하기 위해 시간적/금전적 지출이 크다는 단점이 있습니다. 이 때문에 일반적인 source separation 실험에서는 objective evaluation을 주로 진행하게 됩니다.
사람이 직접 귀로 들었을 때 A모델로 분리된 음원이 B모델로 분리된 음원보다 깨끗할 경우, 각 모델에 대한 평가 지표 값도 이를 잘 반영해야 할 것입니다. 사람이 귀로 듣고 평가했을 때의 결과와 잘 align되게끔, 다양한 objective evaluation metric들이 개발되어 왔습니다. 이를테면 SNR 기반 지표들, PESQ, LPC 기반 지표들이 있는데요. 본 포스팅에서는 SNR 기반 지표들인 SDR, SIR, SAR, SI-SDR을 소개하겠습니다. 우선 SNR이 무엇인지부터 설명하겠습니다.
2-1) SNR(Signal-to-Noise Ratio)
SNR(Signal-to-Noise Ratio, 신호 대 잡음비)은, 이를테면 라디오 송수신 및 전화 통화의 품질을 측정하기 위해, 전기전자공학 분야에서 오랫동안 사용되어 온 메트릭입니다. 일반적으로 아래와 같이 로그 스케일로 계산하며, 단위는 db(데시벨)을 사용합니다. 아래 공식에서 P_noise는 잡음을 나타내고, P_signal은 깨끗한 target source를 의미합니다. 잡음이 섞여 있는 noisy source로부터 분리된 target source의 차를 계산하여 P_noise를 구할 수 있고, 아래 공식을 통해 SNR을 계산함으로써 분리 모델의 성능을 평가할 수 있습니다.

이미지 출처: Wikipedia 하지만 SNR을 source separation 성능 평가 지표로 사용한다기보다는, "실험 환경을 SNR 몇 db로 구성했다"는 식으로 소음 수준을 나타내는 것이 일반적입니다. 소음 환경이 0db라는 것은 목소리랑 잡음이 비슷한 수준이라고 볼 수 있겠죠. 보통 시끄러운 환경이라 함은 SNR은 음수 값인 경우를 나타냅니다. 논문들을 읽다보면 "실제 실험 환경은 SNR ~db"라거나, "잡음을 SNR ~db로 섞어서 인위적으로 생성한 mixture"라는 식의 표현들을 자주 접할 수 있습니다.
2-2) SDR (Signal-to-Distortion Ratio)
SDR(Signal-to-Distortion Ratio), SIR(Signal to Interference Ratio), SAR(Signal to Artifacts Ratio) 모두 SNR로부터 파생된 메트릭인데요. SDR은 전반적인 에러를 반영한 메트릭이고, SIR과 SAR은 각각 interference와 artifact에 대한 target source의 에너지비를 나타냅니다. Interference와 artifact라는 용어가 생소한 분들을 위해 부연 설명을 해보겠습니다.
인풋으로 noisy source mixture가 주어지면, 그로부터 깨끗한 target source를 분리해내는 것이 source separation 모델의 목적입니다. 이 때 깨끗한 target source의 참값(ground truth)를 𝑠_target라고 표현하고, 모델이 추출해낸 target source를 𝑠̂_𝑖라고 표현할 수 있습니다. 직관적으로 생각해보면 모델이 추출해낸 target source와, 실제 target source가 유사할 수록 모델의 성능이 우수하다고 볼 수 있겠죠. 하지만 실제로는 모델이 추출해낸 target source에는 에러가 있을 수 밖에 없는데요, 그 에러를 보다 세분화시킨 것을 공식으로 나타내면 아래와 같습니다.

이미지 출처: https://source-separation.github.io Interference는 분리된 음원에 남아있는 간섭 신호들을 의미합니다. 예를 들어 노래에서 보컬, 기타, 베이스 소리들을 분리해내려고 하는데, 분리된 기타 소리에 흐릿하게 목소리가 남아있을 경우 이를 음향 공학에서는 spill라고 표현하는데요. 이러한 spill들을 interference error라고 볼 수 있습니다. Artifact는 source가 분리되는 과정에서 생긴 신호 자체의 결함을 의미합니다. 이를테면 phase를 추정하여 오디오를 재 생성하는 과정에서 발생하는 glitch는 artifact에 해당됩니다.
이해를 돕기 위해 친숙한 예시를 한 번 들어보겠습니다. (사실 코로나 때문에 노래방도 못 가서 친숙하진 않네요 이제..) 노래방 기계에 넣기 위해 노래로부터 MR을 추출하려면 보컬의 목소리를 지워야 하겠죠. 보컬, 기타, 베이스, 드럼이 모두 섞여 있는 곡으로부터 보컬의 목소리를 지워야 하는 이 상황에서는 SAR이 중요할까요, SIR이 중요할까요? SIR이 낮은 경우는 MR에 보컬의 목소리가 흐릿하게 남아있다는 것이고, SAR이 낮은 경우는 배경 음원이 다소 지직거린다는 것으로 볼 수 있습니다. 즉 노래방 기계에 넣을 MR를 생성하는 경우, SIR이 조금 낮더라도 괜찮지만 SAR은 낮으면 안 되겠죠.
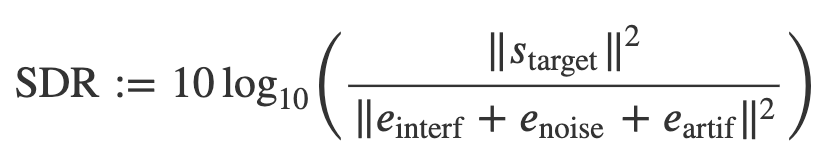
이미지 출처: https://source-separation.github.io SDR 공식은 위와 같고, SAR과 SIR은 분모 항이 interference 에러 또는 artifact 에러로만 구성됩니다. SDR, SAR, SIR 모두 단위는 db(데시벨)이며 그 값이 클 수록 분리가 잘 되었다는 것을 의미합니다. 일반적으로 SDR을 종합적인 성능 지표로 나타내지만, 구체적인 source separation task에 따라 SIR 또는 SAR를 독립적으로 비교 분석하는 것도 필요합니다.
2-3) SI-SDR(Scale-Invariant SDR)
Noisy mixture로부터 target source가 잘 분리되었는지 그 분리 성능 자체를 제대로 평가해야 하는데, 만약 지표로 계산된 값이 scale의 영향을 크게 받는다면 문제가 있습니다. Noisy mixture의 크기(amplitude)만을 줄였을 뿐인데, 계산된 값이 커지거나 작아지면 올바른 평가 지표라고 볼 수 없을 것입니다. SDR – HALF-BAKED OR WELL DONE?라는 논문의 저자들은 앞서 소개한 SDR라는 메트릭이 scale의 영향을 받는다고 지적하며, SI-SDR(Scale-Invariant SDR)라는 메트릭을 제시합니다.
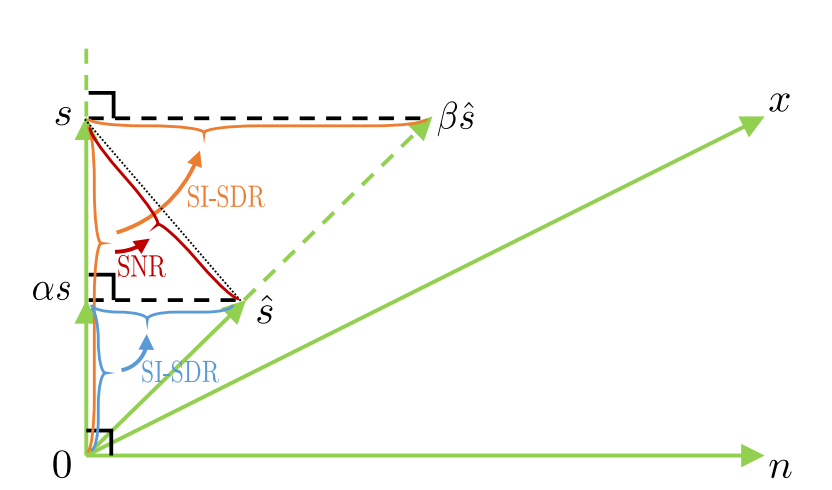
이미지 출처: https://arxiv.org/pdf/1811.02508.pdf 논문에 등장하는 그림을 통해 SI-SDR의 아이디어를 직관적으로 설명하겠습니다. 아래 그림에서 n과 s는 각각 noise와 target source를 나타내고, x는 n+s 즉 noisy mixture를 나타냅니다. 𝑠̂는 모델의 아웃풋, 즉 target source의 예측값을 나타냅니다. 앞서 소개했던 SDR의 공식이 s와 (s-𝑠̂)에 대한 L2 norm 비율에 로그를 취한 값이라는 것을 기억한다면, 뭔가 이상하다는 것을 알 수 있습니다. 아래 그림과 같이 target source s와, residual인 (s-𝑠̂)가 orthogonal하지 않다면 SDR이 항상 양수가 되겠죠?


이 때문에 residual과 target source가 orthogonal하게끔 스케일을 조정해야 하는데요. Target source인 s의 스케일을 조정하거나, estimated target source인 𝑠̂의 스케일을 조정해서 계산된 SDR 값이 같아야 할 것입니다. 참고로 s와 𝑠̂가 주어졌을 때, s에 orthogonal한 𝑠̂ 선상의 벡터는 계산할 수 있기 때문에 베타(beta)는 변수가 아닙니다. 이를 등식으로 나타낸 것이 위 그림의 좌측이고, 계산된 알파(alpha)를 대입한 SI-SDR 공식은 우측과 같습니다.
본 포스팅을 통해 noise suppression라는 task에 대해 기본적인 배경 지식과 성능 평가 지표들을 알아보았습니다. 비록 수식이 조금 등장하기는 하지만, 나름의 흐름이 있기 때문에 이해하는 데에 큰 어려움은 없었을 것입니다. 다음 포스팅에서는 noise suppression 및 dereverberation에 딥러닝이 어떻게 활용되는지에 대해 소개하겠습니다.